
Today, I’ll tell you how to use lambda and pandas modules together, which can greatly improve the efficiency of data analysis and mining.
Importing modules and reading data
Our first step is to import the module and the data set
import pandas as pd
df = pd.read_csv(“IMDB-Movie-Data.csv”)
df.head()
Creating a new column
Generally we create a new column by doing some simple mathematical operations on top of the existing two columns, for example
df[‘AvgRating’] = (df[‘Rating’] + df[‘Metascore’]/10)/2
But if you want to create a new column is quite complex calculation to get, then lambda method is necessary to be applied to a lot of, we first to define a function method
def custom_rating(genre,rating):
if ‘Thriller’ in genre:
return min(10,rating+1)
elif ‘Comedy’ in genre:
return max(0,rating-1)
elif ‘Drama’ in genre:
return max(5, rating-1)
else:
return rating
We use different ratings for different categories of movies, for example, for “Thriller”, the rating is the smallest of “original rating +1” and 10, while for “Comedy “then we apply this custom function to the DataFrame data set by using the apply method and the lambda method
df[“CustomRating”] = df.apply(lambda x: custom_rating(x[‘Genre’], x[‘Rating’]), axis = 1)
1
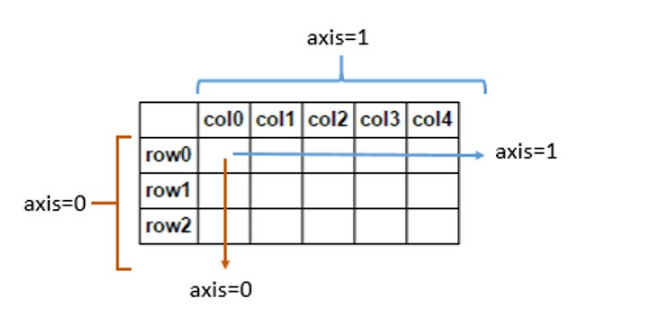
We need to clarify the role of the axis parameter here, where axis=1 means across columns and axis=0 means across rows, as shown below
Filtering data
It is relatively easy to filter data in pandas, you can use the & | ~ operators, the code is as follows
# single condition, the rating is greater than 5 points
df_gt_5 = df[df[‘Rating’]>5]
# multiple conditions: AND – meet both rating higher than 5 and votes greater than 100000
And_df = df[(df[‘Rating’]>5) & (df[‘Votes’]>100000)]
# Multiple conditions: OR – meet rating higher than 5 or votes greater than 100000
Or_df = df[(df[‘Rating’]>5) | (df[‘Votes’]>100000)]
# Multiple conditions: NOT – will meet the rating higher than 5 or votes greater than 100000 to exclude the data
Not_df = df[~((df[‘Rating’]>5) | (df[‘Votes’]>100000))]
These are very simple and common examples, but if we want to filter out the movie title length greater than 5, if we also use the above approach will be reported as an error
df[len(df[‘Title’].split(” “))>=5]
output
AttributeError: ‘Series’ object has no attribute ‘split’
Here we still use a combination of apply and lambda to achieve the above functionality
# Create a new column to store the length of each movie name
df[‘num_words_title’] = df.apply(lambda x : len(x[‘Title’].split(” “))),axis=1)
# filter out the film name length greater than 5
new_df = df[df[‘num_words_title’]>=5]
Of course, if you think the above method is a bit tedious, you can also be a step
new_df = df[df.apply(lambda x : len(x[‘Title’].split(” “))>=5,axis=1)]
For example, if we want to filter out those movies whose box office is below the average for the year, we can do it like this.
We start by summing up the yearly box office averages with the following code
year_revenue_dict = df.groupby([‘Year’]).agg({‘Revenue(Millions)’:np.mean}).to_dict()[‘Revenue(Millions)’]
Then we define a function to determine if there is a case where the film’s box office is below the year’s average, returning a boolean value
def bool_provider(revenue, year):
return revenue<year_revenue_dict[year]
Then we apply to the data set by combining the apply method and the lambda method
new_df = df[df.apply(lambda x : bool_provider(x[‘Revenue(Millions)’],x[‘Year’]),axis=1)]
When we filter the data, we mainly use the .loc method, which can also be used in conjunction with the lambda method, for example, we want to filter the movies with ratings between 5 and 8 and their box office, the code is as follows
df.loc[lambda x: (x[“Rating”] > 5) & (x[“Rating”] < 8)][[“Title”, “Revenue (Millions)”]]
Transforming the data type of a specified column
Usually we transform the data type of the specified column by calling the astype method, for example, we transform the data type of the column “Price” to integer data, the code is as follows
df[‘Price’].astype(‘int’)
An error message will appear as follows
ValueError: invalid literal for int() with base 10: ‘12,000’
So when there is data like “12,000”, calling the astype method to implement data type conversion will report an error, so we also need to combine apply and lambda to clean the data, the code is as follows
df[‘Price’] = df.apply(lambda x: int(x[‘Price’].replace(‘,”, ”)), axis=1)
Visualization of method invocation process
Sometimes when we are dealing with a large data set, it takes a long time to call the function method, so this time we need a progress bar to show us the progress of data processing at all times, it will be much more intuitive.
Here we use the tqdm module, which we will import
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
Then replace the apply method with progress_apply, the code is as follows
df[“CustomRating”] = df.progress_apply(lambda x: custom_rating(x[‘Genre’],x[‘Rating’]),axis=1)
output
When the lambda method meets if-else
Of course, we can also use if-else in lambda custom functions, as follows
Bigger = lambda x, y : x if(x > y) else y
Bigger(2, 10)
output
Of course, many times we may have more than one set of if-else, so it’s a bit tricky to write, the code is as follows
df[‘Rating’].apply(lambda x: “low rated movies” if x < 3 else (“medium rated movies” if x >= 3 and x < 5 else (“high rated movies” if x >= 8 else “worth watching”)
At this point, it is still recommended to customize the function here, by using the apply and lambda methods together.


