
If a crawler engineer, the hand does not take out some available proxy IP, more or less say not out, after all, we face a variety of anti-crawl scenarios every day, no proxy, the work is really not good to start, so the eraser has a weekly “small task” to find a stable proxy source.
Today in the swim in the Internet, looking for a proxy IP, found a new proxy site, that must try a hand, and this site certification to send traffic, the site name is called IPIDEA, is a site specializing in overseas agents.
After registration, immediately after the customer service phone to send traffic, this service is not to say.
Here you can register while learning some of the following concepts, the knowledge points and intermediate crawler engineer closely related! If you are still in the learning stage, this blog will allow you to advance to the intermediate knowledge points.
What is a residential proxy IP
Residential IP address is an IP address bound to a physical device, unlike dynamic IP, the server will identify the residential IP as a real person, with higher security and stability, also for this reason, we can change our location to a home address in various countries and regions of the world, so as to achieve access to the target site from a specified location and avoid geographical restrictions.
If you use a residential proxy IP, you will be able to play the game without being locked out of the zone.
Why use a residential proxy
There must be some reason why you want to hide your IP address, and as a crawler engineer, you will definitely use it, such as web crawling, ad verification, internet marketing ……. If you are learning Python crawling and are not familiar with the residential proxy IP usage scenario, you can just go to the proxy IP site and learn about it. The product site that provides the solution must have the most needed technology in the market.
Proxies in action
The target site already has, the following need to collect proxy data, after all, as a programmer can not manually obtain IP every time, open the menu bar in the [proxy service], the results directly found API Demo, good guys, really convenient.
In practice, Eraser tested a variety of proxy types, such as API link form, account secret authentication form, IP port form. And as a proxy platform, ipidea supports the protocol type, http/https/socks5, to meet the needs of common scenarios in practice.
After you click API (you need to register your real name), get the API link
Copy the above address, fill in the code after the picture below, you can implement the proxy IP extractor.
The test code is shown below.
# coding=utf-8
# ! /usr/bin/env python
import json
import threading
import time
import requests as rq
headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0”,
“Accept”: “text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8”,
“Accept-Language”: “zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2”,
“Accept-Encoding”: “gzip, deflate, br”
}
testUrl = ‘https://api.myip.la/en?json’
# Core operations
def testPost(host, port):
proxies = {
‘http’: ‘http://{}:{}’.format(host, port),
‘https’: ‘http://{}:{}’.format(host, port),
}
res = “”
while True:
try:
res = rq.get(testUrl, proxies=proxies, timeout=5)
# print(res.status_code)
print(res.status_code, “****”, res.text)
break
except Exception as e:
print(e)
break
return
class ThreadFactory(threading:)
def __init__(self, host, port):
threading.Thread.__init__(self)
self.host = host
self.port = port
def run(self):
testPost(self.host, self.port)
# Extract the proxy’s link json type return value
tiqu = ‘http://api.proxy.ipidea.io/getProxyIp… Just copied the address’
while 1 == 1:
resp = rq.get(url=tiqu, timeout=5)
try:
if resp.status_code == 200:
dataBean = json.loads(resp.text)
else:
print(“Failed to fetch”)
time.sleep(1)
continue
except ValueError:
print(“Failed to get”)
time.sleep(1)
continue
else:
print(“code=”, dataBean[“code”])
code = dataBean[“code”]
if code == 0:
threads = []
for proxy in dataBean[“data”]:
threads.append(ThreadFactory(proxy[“ip”], proxy[“port”]))
for t in threads:
t.start()
time.sleep(0.01)
for t in threads:
t.join()
# break
time.sleep(1)
In practice, you can get one IP at a time, just follow the API parameter description and modify the request address.
———- ——
Copyright: This article is an original article by CSDN blogger “Dream Eraser” and follows the CC 4.0 BY-SA copyright agreement, please include the original source link and this statement.
Link to the original article: https://blog.csdn.net/hihell/article/details/125840889
In practice, you can get one IP at a time, you only need to follow the API parameters to modify the request address.
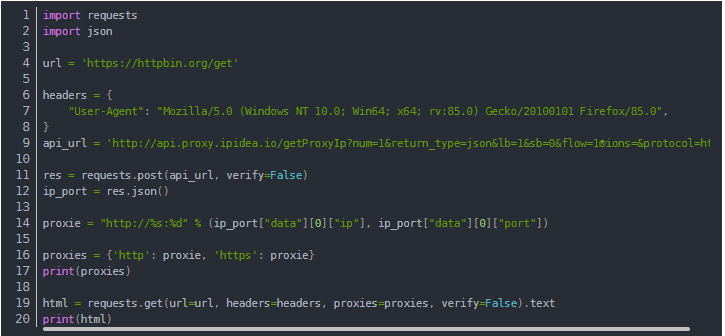
Using Proxies in Python
Once you have obtained the proxy IP, you can use the requests module to complete the proxy request.
The test code is shown below.
import requests
import json
url = ‘https://httpbin.org/get’
headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0”,
}
api_url = ‘http://api.proxy.ipidea.io/getProxyIp?num=1&return_type=json&lb=1&sb=0&flow=1®ions=&protocol=http’
res = requests.post(api_url, verify=False)
ip_port = res.json()
proxie = “http://%s:%d” % (ip_port[“data”][0][“ip”], ip_port[“data”][0][“port”])
proxies = {‘http’: proxie, ‘https’: proxie}
print(proxies)
html = requests.get(url=url, headers=headers, proxies=proxies, verify=False).text
print(html)
In the official use of the proxy, you also need to test whether the proxy is available, here the eraser used the IP detection tool, found that the IP provided by ipidea are quality IP, low latency, very good ~
Using Proxies in Browsers
If you are not a Python crawler engineer, just choose a proxy tool, or want to apply the proxy to the browser, in this proxy service platform, also found the relevant tutorials, and written in great detail.


